gating linear units
“We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence.” – Noam Shazeer
Activation functions are a crucial component of every neural network. They introduce non-linearity to the model, allowing it to learn complex patterns in the data.
$$ \begin{align} y = g( g( x W_1 + b_1)W_2 + b_2) \end{align} $$where $g$ is the activation function, $W_1$ and $W_2$ are the weight matrices, $b_1$ and $b_2$ are the bias vectors, and $x$ is the input vector.
$$ \begin{align} y = (xW_1 + b_1 )W_2 + b_2 = x W_1W_2 + b_1W_2 + b_2 = xW + b \end{align} $$We would end up with a linear model, which is not very useful for learning complex mappings.
In this post, we will explore activation functions derived from the Gated Linear Unit (GLU) as introduced in Shazeer et al. (2020), and their effectiveness in learning a task when applied to the feed-forward module in the Transformer architecture.
Introduction
The Transformer model processes the input data by alternating between multi-head attention and “point-wise feed-forward networks” (FFN). In its basic form, the FFN is typically applied on each input token independently, and consists of two linear layers with a non-linear activation function in between.
$$ \begin{align} \text{ReLU}(x) = \max(0, x) \end{align} $$$$ \begin{align} \text{FFN}_\text{ReLU}(x, W_1, W_2, b_1, b_2) = \max (0, x W_1 + b_1) W_2 + b_2 \end{align} $$$$ \begin{align} \text{GELU}(x) = x P(X \le x) = x \Phi(x) = x \cdot \frac{1}{2} \left( 1 + \text{erf} \left(x / \sqrt{2} \right) \right) \end{align} $$$$ \begin{align} \text{GELU}(x) \approx 0.5 \cdot x \cdot ( 1 + \tanh ( \sqrt{2/\pi} \cdot (x + 0.044715 \cdot x^3) )) \end{align} $$$$ \begin{align} \text{FFN}_\text{GELU}(x, W_1, W_2, b_1, b_2) = x \Phi(x W_1 + b_1) W_2 + b_2 \end{align} $$Ramachandran et al. (2017) introduced by the Swish activation function:
$$ \begin{align} \text{Swish}_\beta(x) = x \cdot \sigma(\beta x) = x \cdot \frac{1}{1 + e^{-x}} \end{align} $$$$ \begin{align} \text{SiLU}(x) = x \cdot \sigma(x) \end{align} $$$$ \begin{align} \text{FFN}_\text{Swish}(x, W_1, W_2, b_1, b_2) = x \sigma(x W_1 + b_1) W_2 + b_2 \end{align} $$where we assume $\beta = 1$ for simplicity.
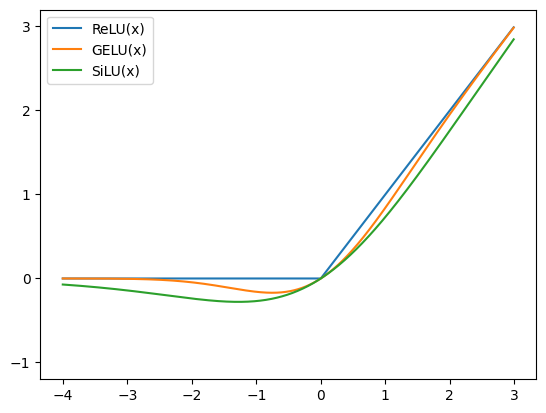
Above we can see the plots of the activation functions discussed in this section.
Gated Linear Units (GLU) and Variants
$$ \begin{align} \text{GLU}(x, W, V, b, c) = \sigma(x W + b) \odot (x V + c) \end{align} $$$$ \begin{align} \text{Bilinear}(x, W, V, b, c) = (x W + b) \odot (x V + c) \end{align} $$$$ \begin{align} \text{ReGLU}(x, W, V, b, c) &= \text{ReLU}(xW + b) \odot (xV + c) \\ \text{GEGLU}(x, W, V, b, c) &= \text{GELU}(xW + b) \odot (xV + c) \\ \text{SwiGLU}(x, W, V, b, c) &= \text{Swish}_\beta(xW + b) \odot (xV + c) \end{align} $$$$ \begin{align} \text{FFN}_\text{GLU} (x, W, V, W_2) &= (\sigma(x W) \odot x V)W_2 \\ \text{FFN}_\text{Bilinear} (x, W, V, W_2) &= (x W \odot x V)W_2 \\ \text{FFN}_\text{ReGLU} (x, W, V, W_2) &= (\text{ReLU}(x W) \odot x V)W_2 \\ \text{FFN}_\text{GEGLU} (x, W, V, W_2) &= (\text{GELU}(x W) \odot x V)W_2 \\ \text{FFN}_\text{SwiGLU} (x, W, V, W_2) &= (\text{Swish}_1(x W) \odot x V)W_2 \end{align} $$where the bias term is ommited for simplicity.
Notice that all of these layers have 3 weight matrices as opposed to the original 2 in the FFN module. Appropriately, the dimensionality of the projections are adjusted to match the total number of parameters in the original FFN module so that a fair comparison can be made.
Experiments
Using the above FFN proposals, Shazeer et al. (2020) conducted experiments in order to evaluate the effectiveness of the different activation functions.
A T5 model is trained on a denoising objective of predicting missing text segments, and subsequently fine-tuned on various language understanding tasks.
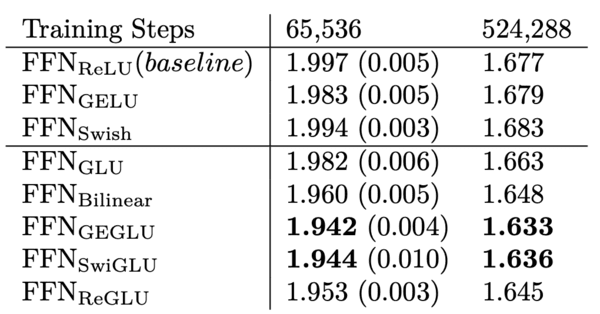
First, they evaluated the log-perplexity by training the model on the C4 dataset, and evaluating it on a held-out validation set. The GEGLU and SwiGLU activation functions outperformed the rest.
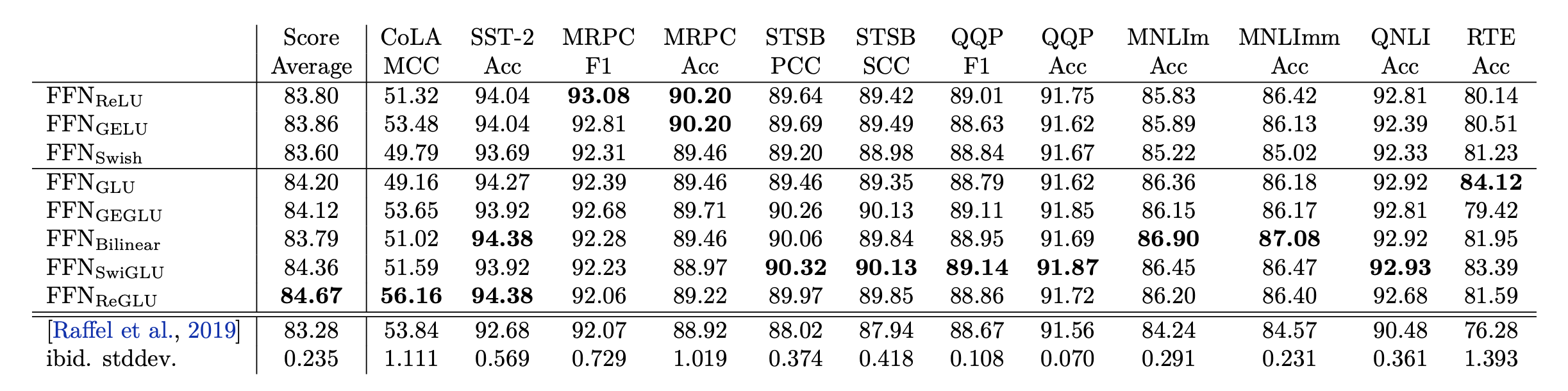
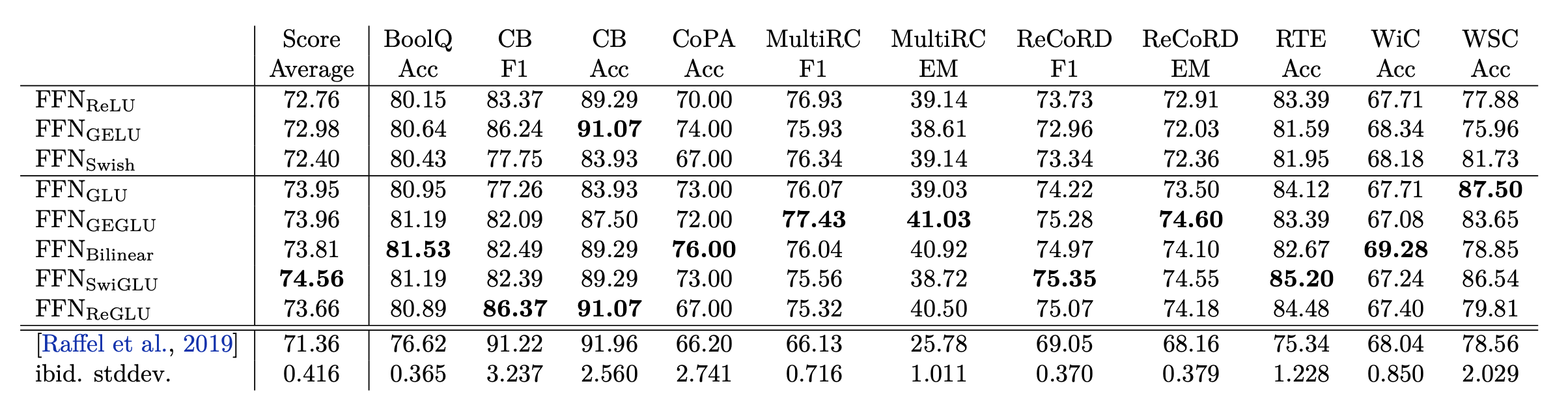
Next, they fine-tune each individual pre-trained model on a set of language understanding tasks from the GLUE and SuperGLUE benchmarks. While the results are noisy, the GLU variants perform best on all of the tasks.
Conclusion
In this post, we have explored several variations of the Gated Linear Unit (GLU) activation function, and their effectiveness in learning a task when applied to the feed-forward module in the Transformer architecture.
The results suggest that the GEGLU and SwiGLU activation functions outperform the rest in terms of log-perplexity on the C4 dataset, and fine-tuning on various language understanding tasks.