grouped-query attention (gqa)
Natively, Transformers use Multi-Head Attention (MHA) to compute the token representations as functions of the input tokens. However, MHA is computationally expensive, especially during inference, due to the increase of the Key-Value (KV) cache size with each decoded token. One the other hand, Multi-Query Attention (MQA) reduces the memory bandwidth overhead by sharing the same keys and values across all query heads, albeit at the cost of quality degradation.
In order to strike a balance between efficiency and quality, Grouped-Query Attention (GQA) shares the keys and values across a group of query heads, interpolating between MHA and MQA. This allows for a more efficient computation of the token representations while maintaining the quality of the model.
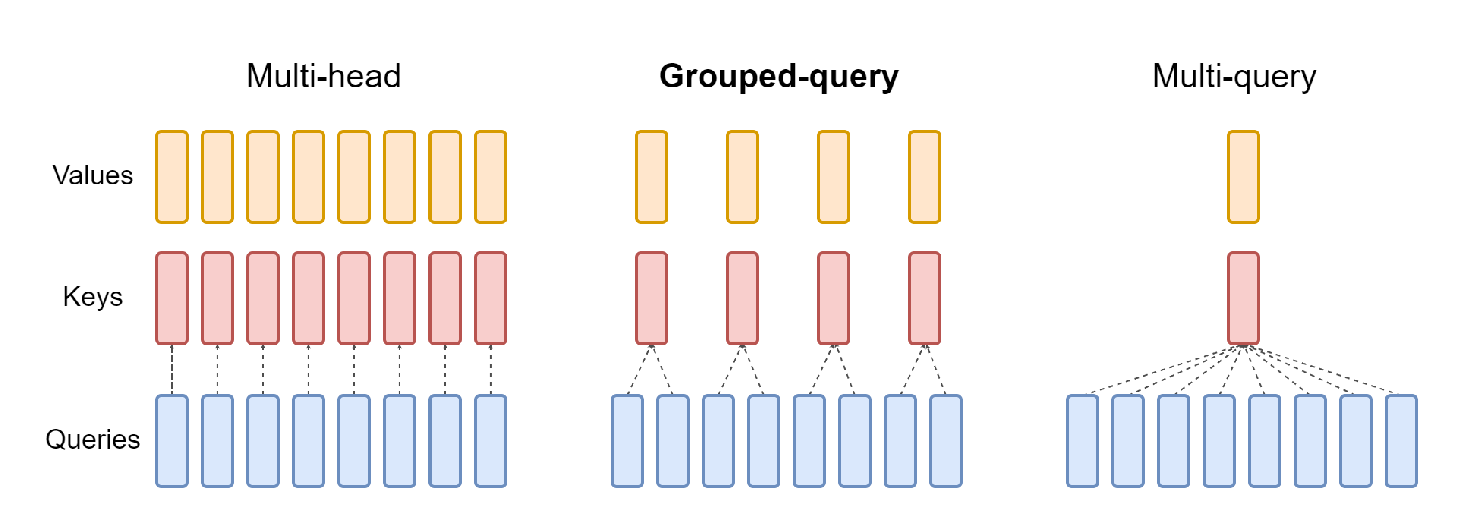
The figure above neatly illustrates the difference between the three attention mechanisms. Multi-head attention has H query, key, and value heads. Multi-query attention shares single key and value heads across all query heads. Grouped-query attention instead shares single key and value heads for each group of query heads, interpolating between multi-head and multi-query attention.
Today, this form of attention is used in several popular State-of-the-Art (SotA) transformer models such as LLaMA and Mistral. Even though SotA models today use GQA from the beginning of the training procedure, Ainslie et al. (2023) originally proposed this method as a way to convert existing Multi-Head checkpoints into Multi-Query or Grouped-Query checkpoints, which is typically done with a small fraction of the original pre-training compute.
Method
Building a Multi-Query or Grouped-Query model from an existing Multi-Head checkpoint involves two steps:
- Converting the Multi-Head checkpoint into a compatible Multi-Query or Grouped-Query checkpoint.
- Additional pre-training to allow the model to adapt to its new structure.
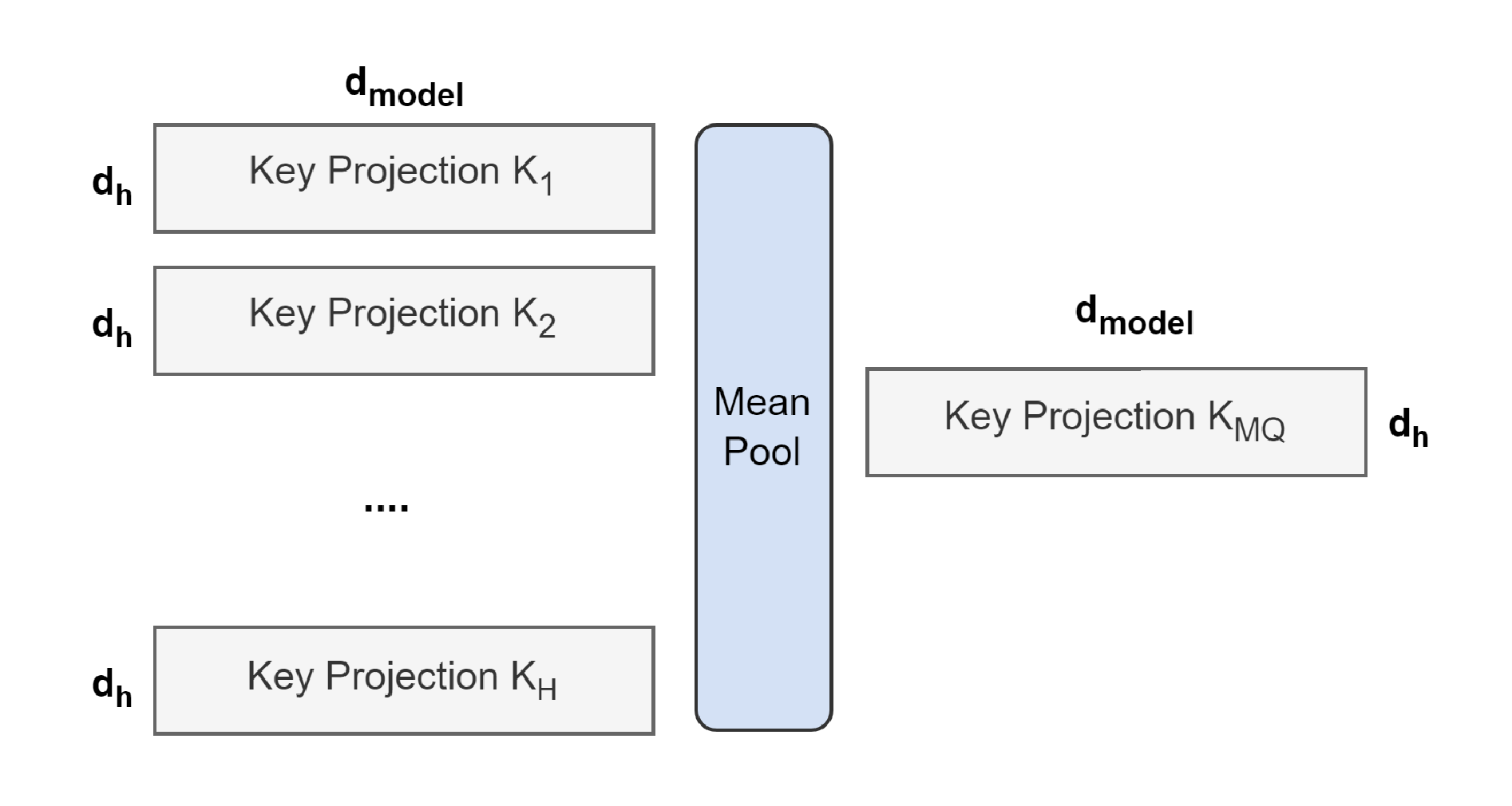
The figure above illustrates the process of converting a Multi-Head checkpoint into a Multi-Query checkpoint. The projection matrices for key and value heads are mean-pooled into single projection matrices, which is found to work better than selecting a single key and value head or randomly initializing new key and value heads from scratch.
Similarly, a Grouped-Query checkpoint is constructed by first dividing the $H$ query heads into $G$ groups, each of which will share a single key head and value head. As before, each group key and value head is constructed by mean-pooling all the original heads within that group.
Once the checkpoints are converted, they are pre-trained for a small proportion of the original training steps on the same pre-training recipe.
Results
The authors examine how various configurations affect model performance and inference time. They evaluate the models on summarization datasets such as CNN/Daily Mail, arXiv, PubMed, MediaSum, and MultiNews, as well as translation and question-answering datasets.
In short, the results show that uptrained GQA models achieve quality close to MHA while being almost as fast as MQA.
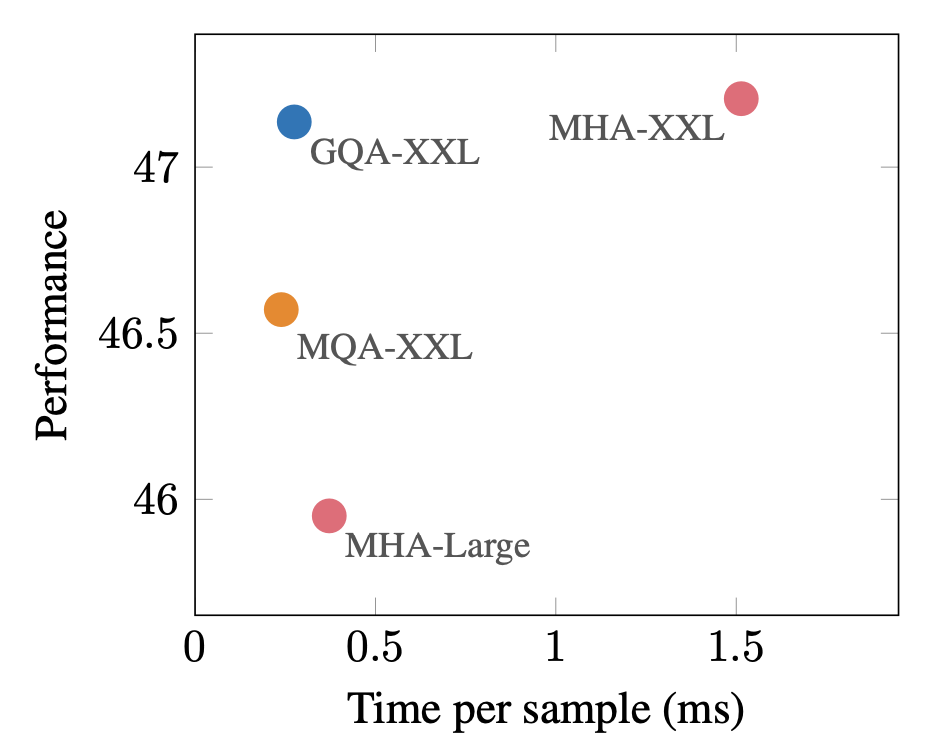
First, they show that a larger uptrained MQA model provides a favorable trade-off relative to MHA models, with higher quality and faster inference than MHA-Large. Moreover, GQA achieves significant additional quality gains, achieving performance close to MHA-XXL with speed close to MQA.
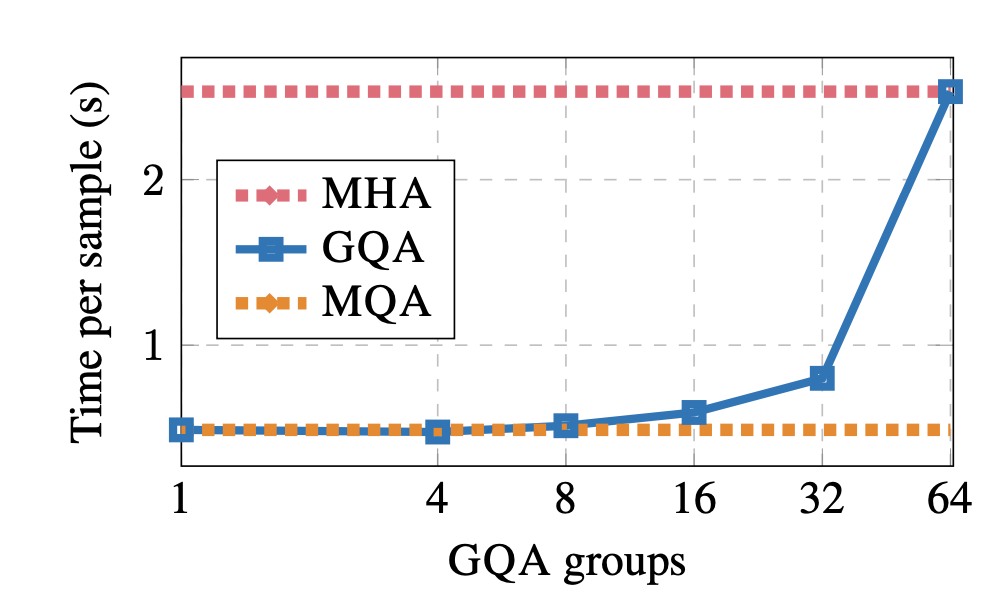
Next, they show that using up to 8 groups in GQA results in modest slowdowns with inference speed, being almost on par with MQA.
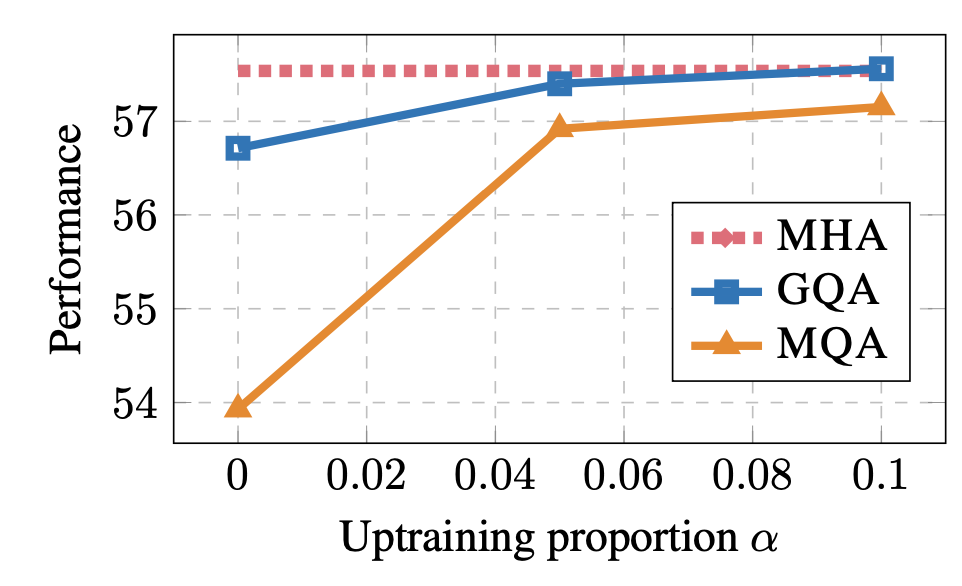
Lastly, they demonstrate that both MQA and GQA largely benefit from 5% uptraining, with GQA almost matching the performance of MHA when uptrained on 10% of the total compute.
Implementation
Following is a minimal implementation of the Grouped-Query Attention mechanism in PyTorch:
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class GQAttention(nn.Module):
def __init__(self, dim, n_heads, n_kv_heads):
super().__init__()
self.dim = dim # embedding dimension
self.n_heads = n_heads # number of query heads
self.n_kv_heads = n_kv_heads # number of key-value heads
self.head_dim = dim // n_heads # dimension of each head
self.wq = nn.Linear(dim, n_heads * self.head_dim, bias=False)
self.wk = nn.Linear(dim, n_kv_heads * self.head_dim, bias=False)
self.wv = nn.Linear(dim, n_kv_heads * self.head_dim, bias=False)
self.wo = nn.Linear(n_heads * self.head_dim, dim, bias=False)
def repeat_kv(self, x):
n_rep = self.n_heads // self.n_kv_heads
if n_rep == 1:
return x
return x.repeat_interleave(n_rep, dim=2)
def forward(self, x):
bsz, seqlen, _ = x.shape
# Compute query, key, and value projections
q = self.wq(x).view(bsz, seqlen, self.n_heads, self.head_dim)
k = self.wk(x).view(bsz, seqlen, self.n_kv_heads, self.head_dim)
v = self.wv(x).view(bsz, seqlen, self.n_kv_heads, self.head_dim)
# Repeat keys and values to match query dimensions
k = self.repeat_kv(k) # (bsz, seqlen, n_heads, head_dim)
v = self.repeat_kv(v) # (bsz, seqlen, n_heads, head_dim)
# Transpose for attention computation
q = q.transpose(1, 2) # (bsz, n_heads, seqlen, head_dim)
k = k.permute(0, 2, 3, 1) # (bsz, n_heads, head_dim, seqlen)
v = v.transpose(1, 2) # (bsz, n_heads, seqlen, head_dim)
# Compute attention scores
scores = torch.matmul(q, k) / math.sqrt(self.head_dim)
attn = F.softmax(scores, dim=-1) # (bsz, n_heads, seqlen, seqlen)
# Compute output
out = torch.matmul(attn, v) # (bsz, n_heads, seqlen, head_dim)
out = out.transpose(1, 2).contiguous().view(bsz, seqlen, -1) # (bsz, seqlen, n_heads * head_dim)
out = self.wo(out) # (bsz, seqlen, dim)
return out
Now, let us test the implementation with a sample input:
dim = 512
n_heads = 8
n_kv_heads = 4
seqlen = 10
batch_size = 2
gqa = GQAttention(dim, n_heads, n_kv_heads)
x = torch.randn(batch_size, seqlen, dim)
output = gqa(x)
print(f"Input shape: {x.shape}")
print(f"Output shape: {output.shape}")
assert x.shape == output.shape
Input shape: torch.Size([2, 10, 512])
Output shape: torch.Size([2, 10, 512])