key-value (kv) cache
Decoder-only models like GPT, LLaMA, Mistral and others generate tokens in an auto-regressive fashion. This means that for a given input, the model predicts the next token, and then concatenates the input with the predicted token to predict the next token, and so on.
However, a naive implementation of this process can be very slow, as the model ends up recalculating the keys and values in the attention mechanism for each input token, even though they should remain the same. The reason why they remain the same is because the attention in the decoder has a causal mask which forces the model at that particular position to only attend tokens preceding it. Therefore, the attention for the previous tokens should remain the same.
To speed up this process, we can cache the keys and values of the attention mechanism, and only calculate the attention for the new token. This is known as Key-Value (KV) caching.
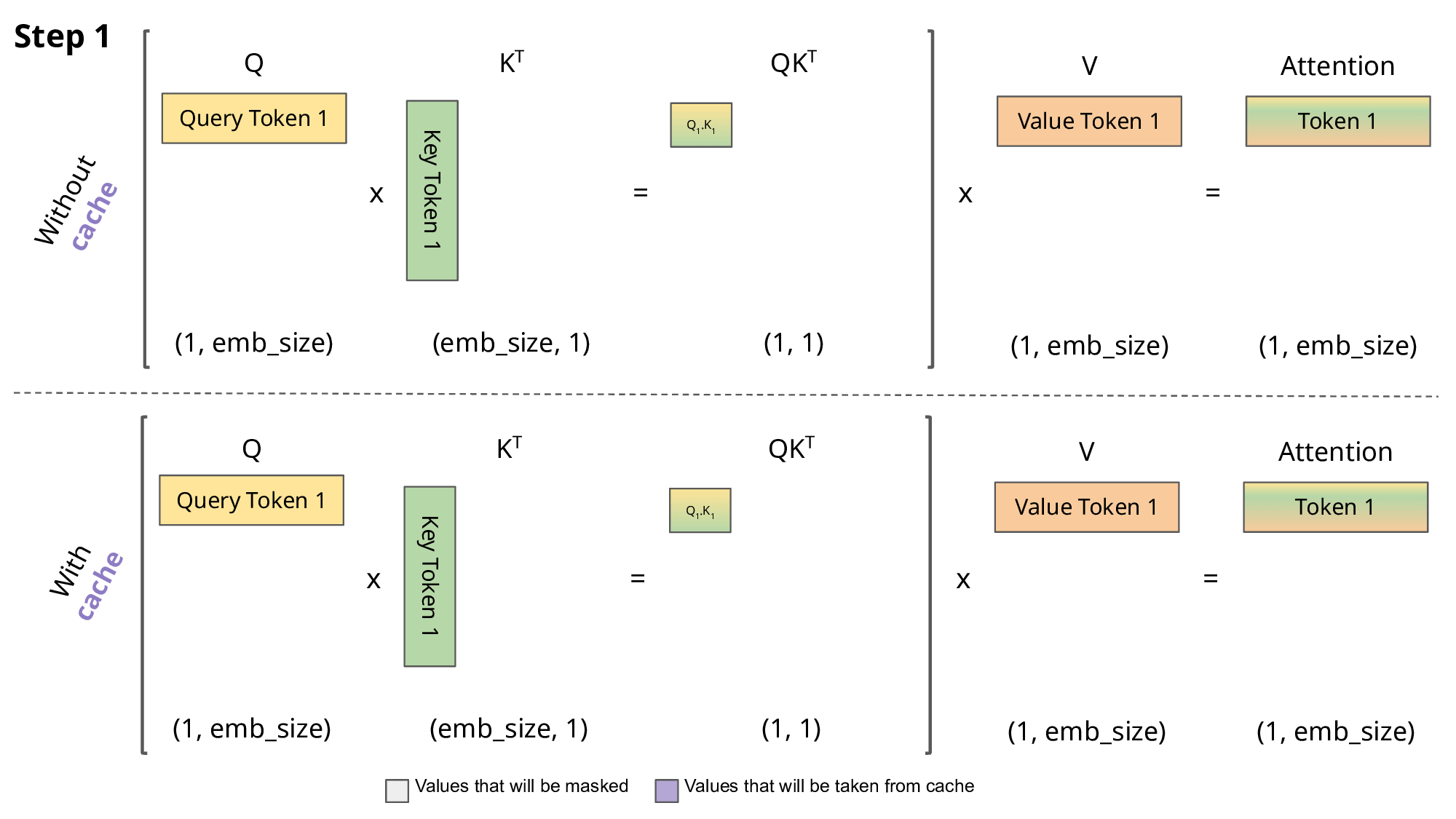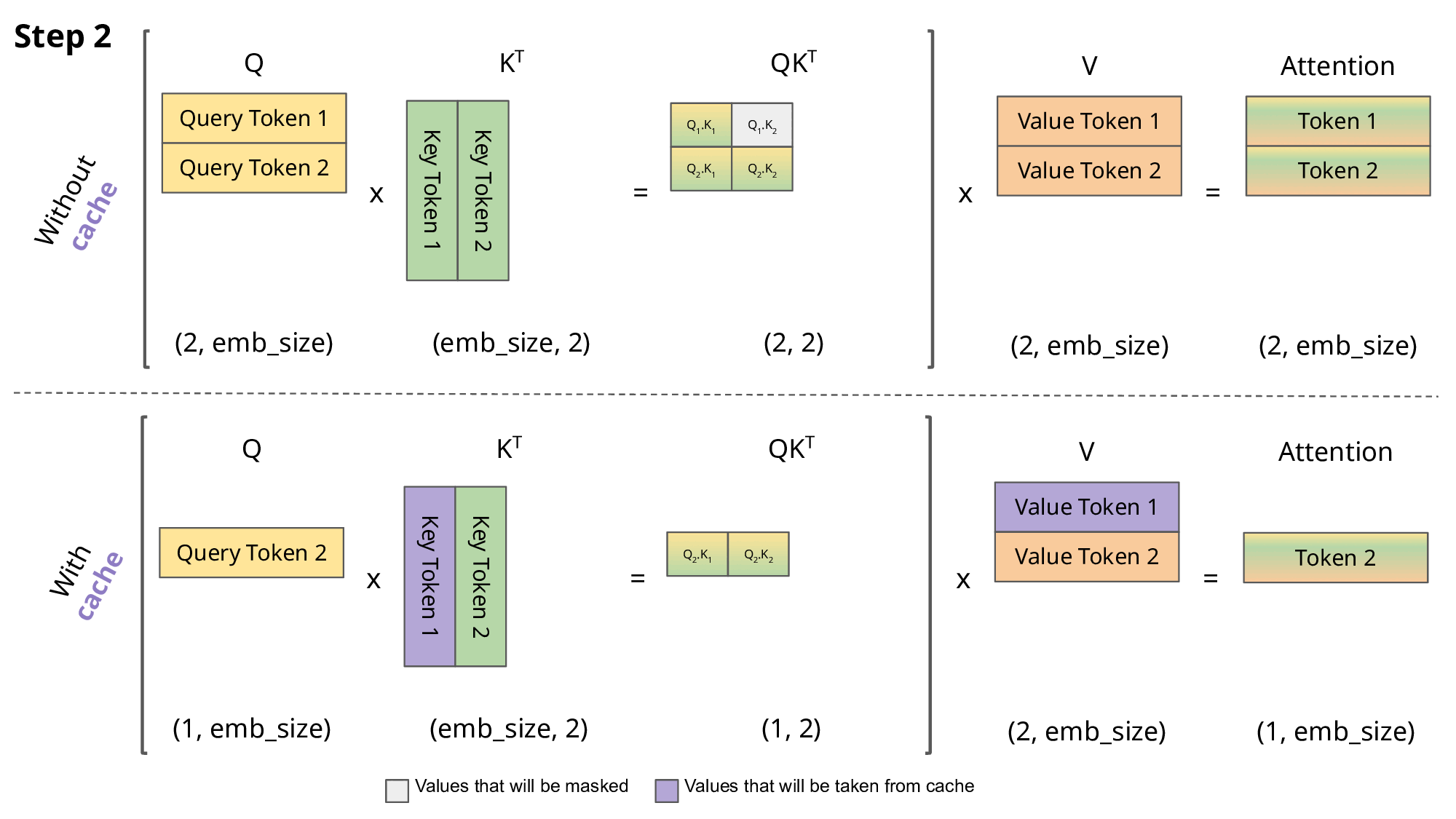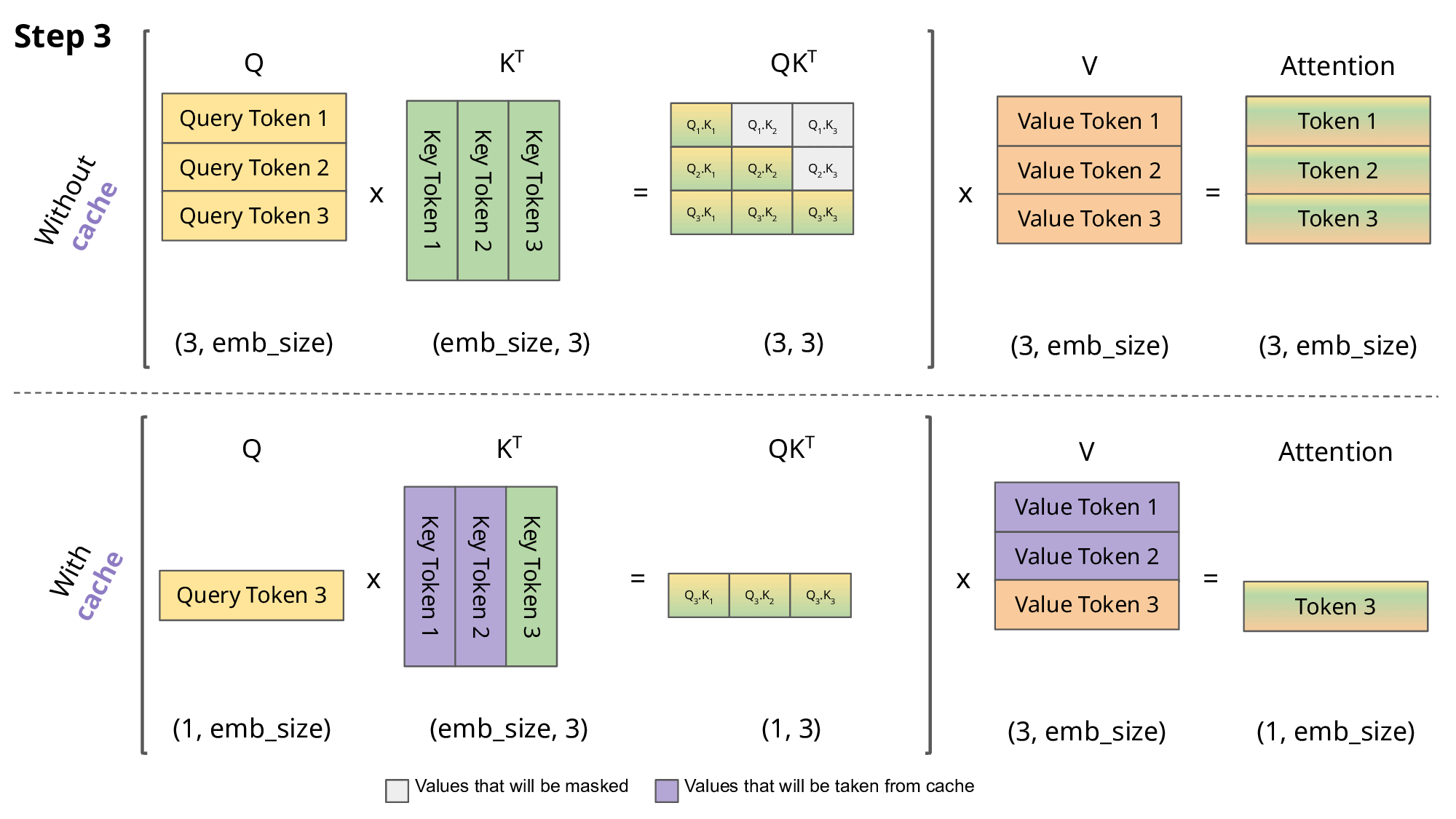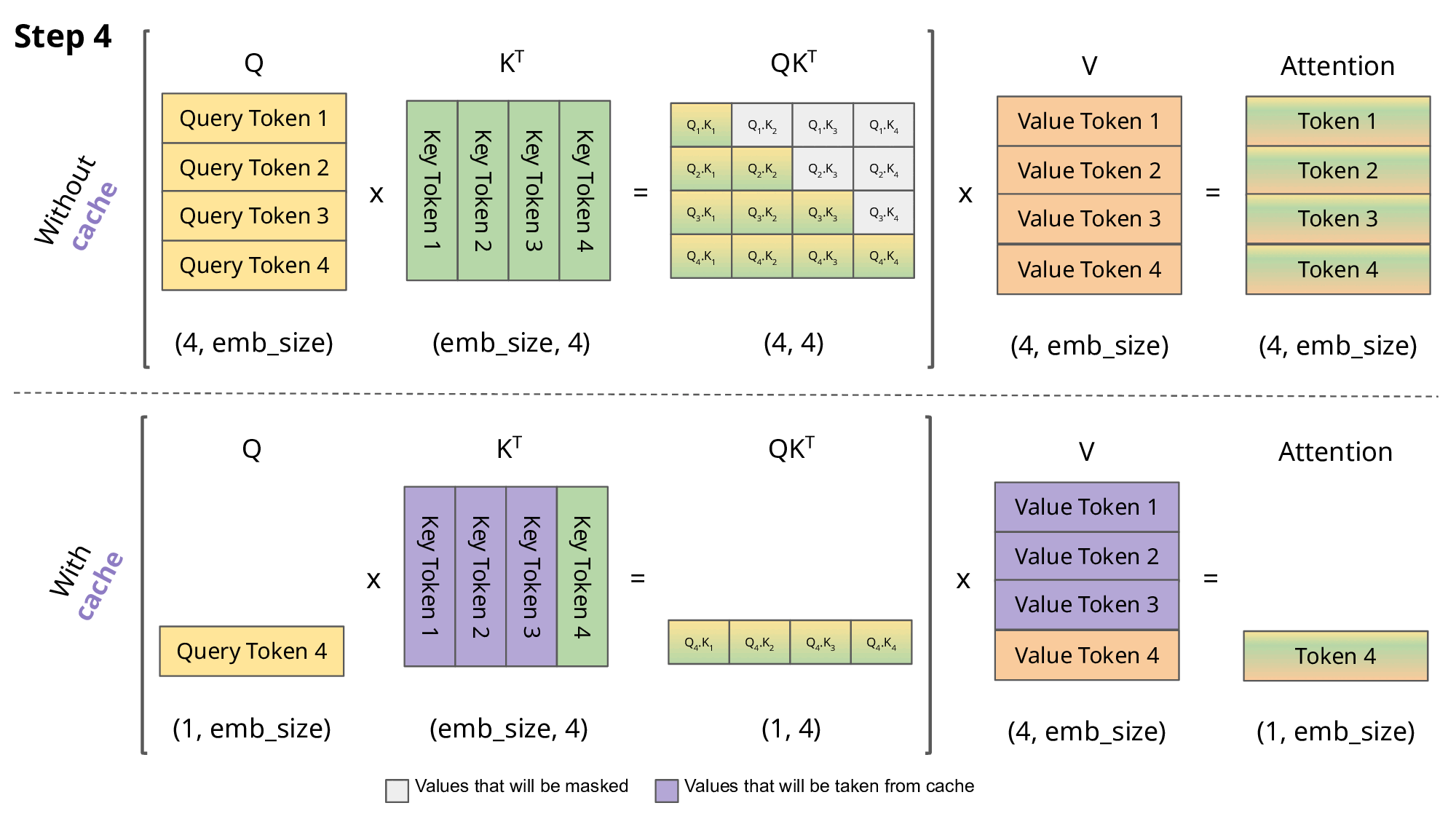
The figure above neatly illustrates the difference between calculating the attention with and without KV caching (source: João Lages’ blog).
While we are gaining speed by using the KV cache, one should note that this increases the memory requirements for running the model. Nevertheless, this is a small price to pay for the significant speedup that it provides.
Following is a minimal PyTorch implementation of the Attention module with KV caching:
import math
import random
import torch
import torch.nn as nn
import torch.nn.functional as F
class AttentionWithKVCache(nn.Module):
def __init__(self, dim, n_heads, max_batch_size, max_seq_len):
super().__init__()
self.dim = dim
self.n_heads = n_heads
self.head_dim = dim // n_heads
self.wq = nn.Linear(dim, n_heads * self.head_dim, bias=False)
self.wk = nn.Linear(dim, n_heads * self.head_dim, bias=False)
self.wv = nn.Linear(dim, n_heads * self.head_dim, bias=False)
self.wo = nn.Linear(n_heads * self.head_dim, dim, bias=False)
# Pre-allocate memory for key and value caches
self.cache_k = torch.zeros((max_batch_size, max_seq_len, n_heads, self.head_dim))
self.cache_v = torch.zeros((max_batch_size, max_seq_len, n_heads, self.head_dim))
def forward(self, x, start_pos):
bsz, seqlen, _ = x.shape
q = self.wq(x).view(bsz, seqlen, self.n_heads, self.head_dim)
k = self.wk(x).view(bsz, seqlen, self.n_heads, self.head_dim)
v = self.wv(x).view(bsz, seqlen, self.n_heads, self.head_dim)
# Update the cache
self.cache_k[:bsz, start_pos:start_pos + seqlen] = k
self.cache_v[:bsz, start_pos:start_pos + seqlen] = v
# Use all preceding keys and values
k = self.cache_k[:bsz, :start_pos + seqlen]
v = self.cache_v[:bsz, :start_pos + seqlen]
q = q.transpose(1, 2)
k = k.permute(0, 2, 3, 1)
v = v.transpose(1, 2)
scores = torch.matmul(q, k) / math.sqrt(self.head_dim)
scores = F.softmax(scores.float(), dim=-1).type_as(q)
output = torch.matmul(scores, v)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
output = self.wo(output)
return output
Let us test the implementation with a simple example:
dim = 512
n_heads = 8
max_batch_size = 2
max_seq_len = 2048
model = AttentionWithKVCache(dim, n_heads, max_batch_size, max_seq_len)
start_pos = 0
for step in range(3):
seqlen = random.randint(1, 5) # simulate variable length input sequences
new_tokens = torch.randn(max_batch_size, seqlen, dim)
output = model(new_tokens, start_pos)
start_pos += seqlen
print(f"Step {step + 1}:")
print(f" Sequence length: {seqlen}")
print(f" Current cache usage: {start_pos}/{max_seq_len}\n")
print(f"Total cache usage: {start_pos}/{max_seq_len}")
Step 1:
Sequence length: 4
Current cache usage: 4/2048
Step 2:
Sequence length: 5
Current cache usage: 9/2048
Step 3:
Sequence length: 3
Current cache usage: 12/2048
Total cache usage: 12/2048
By using the KV cache, we can see that the model is only calculating the attention for the new tokens, while reusing the keys and values from the previous steps. This results in a significant speedup, especially for long sequences.
Note that by manipulating the start position, we can control the cache usage, and clear the cache when needed. For example, if we need to process two different batches, we can reset the start position to 0 before processing the second batch.
for batch in range(2):
print(f"Batch {batch + 1}:")
start_pos = 0
for step in range(3):
seqlen = random.randint(1, 5) # simulate variable length input sequences
new_tokens = torch.randn(max_batch_size, seqlen, dim)
output = model(new_tokens, start_pos)
start_pos += seqlen
print(f" Step {step + 1}:")
print(f" Sequence length: {seqlen}")
print(f" Current cache usage: {start_pos}/{max_seq_len}\n")
print(f"Total cache usage: {start_pos}/{max_seq_len}")
print('----------------------')
Batch 1:
Step 1:
Sequence length: 4
Current cache usage: 4/2048
Step 2:
Sequence length: 2
Current cache usage: 6/2048
Step 3:
Sequence length: 3
Current cache usage: 9/2048
Total cache usage: 9/2048
-----------------------------------
Batch 2:
Step 1:
Sequence length: 4
Current cache usage: 4/2048
Step 2:
Sequence length: 5
Current cache usage: 9/2048
Step 3:
Sequence length: 1
Current cache usage: 10/2048
Total cache usage: 10/2048
-----------------------------------
As is evident from the output, the cache is cleared when processing the second batch, and the model starts afresh with the new keys and values.